# male, female 값을 각각 0과 1로 인코딩한다
sex_i=3embark_i=7fordatainset:sex_i-=1embark_i-=1foriinrange(data.shape[0]):ifdata[i,sex_i]=='male':data[i,sex_i]=0else:data[i,sex_i]=1ifdata[i,embark_i]=='S':data[i,embark_i]=0elifdata[i,embark_i]=='Q':data[i,embark_i]=1else:data[i,embark_i]=2
Data Type Change : int32? –> float64
사유 : 텐서플로를 벡엔드로 사용하는 Keras는 int를 입력으로 받지 않음
1
2
3
# 데이터 형변환
train=train.astype(np.float64)test=test.astype(np.float64)
# keras모델 설계
model=models.Sequential()model.add(layers.Dense(16,activation="relu",input_shape=(6,)))model.add(layers.Dropout(0.3))model.add(layers.Dense(16,activation="relu"))model.add(layers.Dropout(0.3))model.add(layers.Dense(1,activation="sigmoid"))model.compile(optimizer="rmsprop",loss="binary_crossentropy",metrics=["binary_accuracy"])
acc=history.history['binary_accuracy']val_acc=history.history['val_binary_accuracy']loss=history.history['loss']val_loss=history.history['val_loss']epochs=range(1,len(acc)+1)# ‘bo’는 파란색 점을 의미합니다
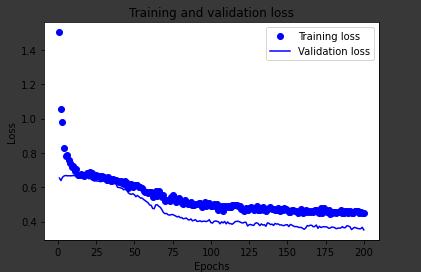
plt.plot(epochs,loss,'bo',label='Training loss')# ‘b’는 파란색 실선을 의미합니다
plt.plot(epochs,val_loss,'b',label='Validation loss')plt.title('Training and validation loss')plt.xlabel('Epochs')plt.ylabel('Loss')plt.legend()plt.show()
결과 :
1
2
3
4
5
6
7
8
9
10
11
12
plt.clf()# 그래프를 초기화합니다
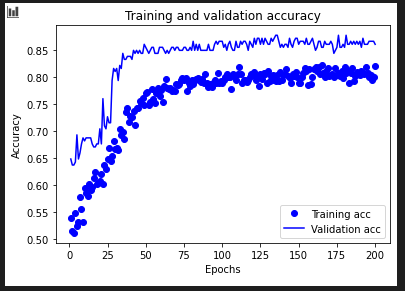
acc=history_dict['binary_accuracy']val_acc=history_dict['val_binary_accuracy']plt.plot(epochs,acc,'bo',label='Training acc')plt.plot(epochs,val_acc,'b',label='Validation acc')plt.title('Training and validation accuracy')plt.xlabel('Epochs')plt.ylabel('Accuracy')plt.legend()plt.show()